
Claude embeddings usually means using Claude-related text for semantic search, clustering, or retrieval, but Anthropic does not position Claude as a dedicated embeddings model family in the same way some providers do; this independent guide explains what that means, where Claude fits, and when to use the Claude API, Claude models, or another approach.

If you arrived looking for a specific Claude model, pricing detail, or whether Claude supports vector-style workflows, the sections below answer that directly and point to the most relevant official Anthropic pages.
- Which model is this?
- What it’s best at
- Where it falls short
- When to pick this model
- Other questions readers ask
- The honest take
Which model is this?
Strictly speaking, “claude embeddings” is not one clearly named Anthropic model in the current public lineup. Claude is a family of generative models made by Anthropic — Opus, Sonnet, and Haiku — and the current active models are Claude Opus 4.7, Claude Sonnet 4.6, and Claude Haiku 4.5. If you mean semantic understanding for retrieval or search, you are usually asking whether Claude can support an embeddings-style workflow rather than asking for a dedicated Claude embeddings endpoint.
- Input from $1 to $5 per million tokens
- Output from $5 to $25 per million tokens
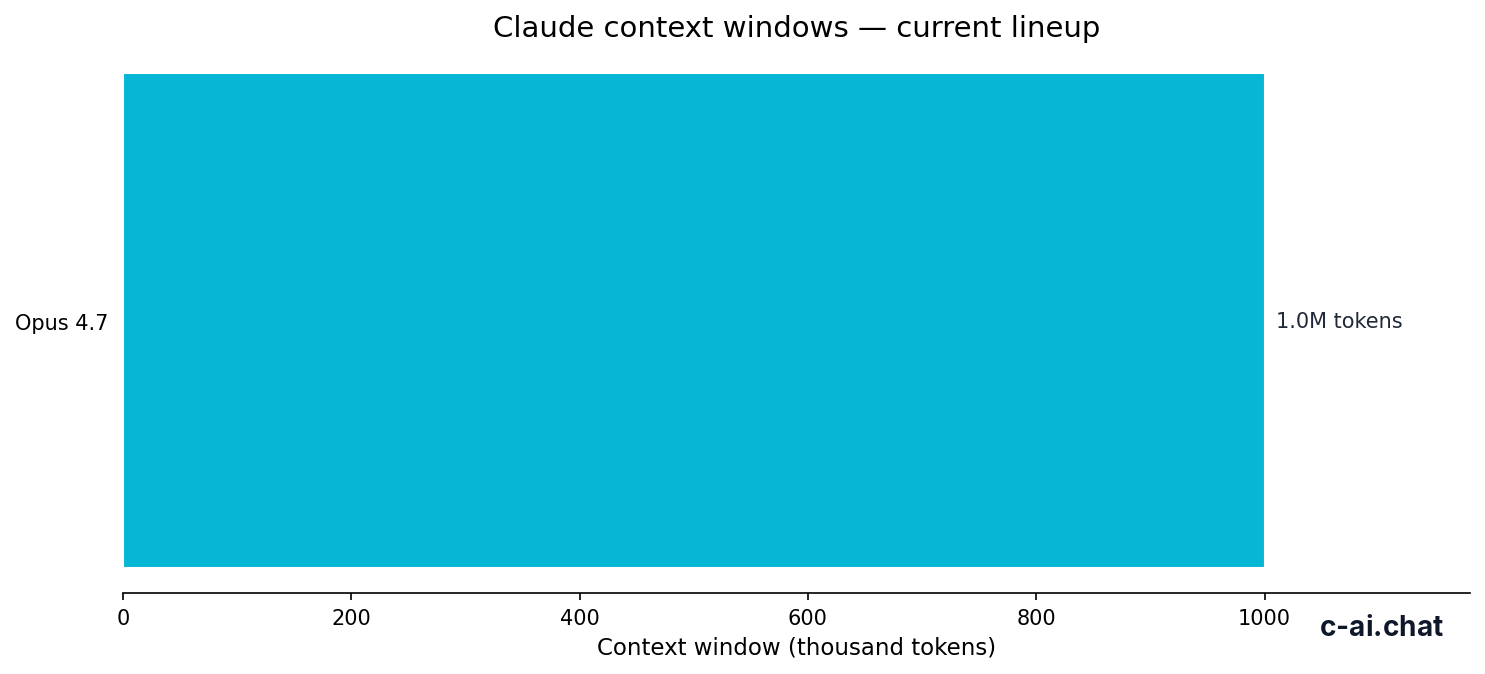
- Context window up to 1,000,000 tokens on Opus 4.7
- Max output 128K on Sonnet 4.6
Here is the practical answer: Claude is very good at understanding meaning, rewriting content into structured labels, extracting entities, summarising documents, and ranking passages for retrieval. Those are jobs many people group under “embeddings” because they sit in the same search-and-RAG pipeline. But on Anthropic’s official pricing and model pages, the published lineup is a set of text generation models rather than a separate, front-and-centre embeddings product family.
| Model | Family | Released | Input price | Output price | Best shorthand use |
|---|---|---|---|---|---|
| Claude Opus 4.7 | Opus | Latest flagship release | $5/M | $25/M | Highest-end reasoning and long-context analysis |
| Claude Sonnet 4.6 | Sonnet | Current balanced model | $3/M | $15/M | Default choice for most production workloads |
| Claude Haiku 4.5 | Haiku | Current fast model | $1/M | $5/M | Speed and low-cost classification or extraction |
What it’s best at
Claude is strongest when you need semantic understanding plus language reasoning in the same workflow. That includes taking messy source text, turning it into clean categories, identifying the most relevant chunks for retrieval, generating metadata, and rewriting passages into forms that work better for search. In other words, Claude often works well one step before embeddings, one step after embeddings, or as the ranking and reasoning layer around them.
Within Anthropic’s lineup, Sonnet 4.6 is usually the best default for these jobs because it balances quality and cost better than Opus 4.7, while Haiku 4.5 is the better pick when you need high-volume lightweight classification or extraction at the lowest price. Opus 4.7 can be worth it for complex retrieval pipelines, long-document indexing logic, or nuanced relevance judgments across very large context windows, but it is harder to justify if your task is simple tagging or cheap batch processing. If you are comparing options broadly, our Claude pricing guide and Claude features overview help frame those trade-offs.
- Semantic classification: assigning topics, intents, document types, or support categories from natural language.
- Retrieval preparation: chunk cleanup, metadata extraction, query rewriting, and passage labelling before indexing.
- Reranking-like tasks: deciding which passages are most relevant to a user question when plain vector similarity is not enough.
- Entity and relation extraction: pulling people, companies, dates, product names, or structured facts from documents.
- Long-context synthesis: comparing multiple source documents inside a single prompt when you need judgment, not just nearest-neighbour matching.
90% off
cached input tokens with prompt caching
That discount matters for repeated retrieval workflows. If your application sends a stable system prompt, fixed instructions, or reused document preamble on many requests, prompt caching can cut the input cost sharply. Anthropic also offers Batch API pricing with 50% off both input and output, which can make offline labelling, enrichment, and indexing jobs much more viable for large datasets.
Where it falls short

Claude is not the clearest answer if you need a plain, purpose-built embeddings endpoint with fixed-dimension vectors, straightforward cosine similarity workflows, and minimal generation overhead. A lot of search pipelines still want exactly that. Claude can help around the retrieval layer, but if your requirement is “give me vectors cheaply and consistently at scale,” you should verify Anthropic’s current API offering first rather than assume the Claude chat models are a drop-in substitute.
- Not the simplest fit for vector-native pipelines: many teams want deterministic embeddings outputs, not a general text model.
- Opus 4.7 can be expensive for bulk indexing: $5/M input and $25/M output is hard to justify for lightweight enrichment tasks.
- Haiku 4.5 may miss nuance: fast and cheap does not always mean best semantic judgment on ambiguous content.
- Generative outputs need validation: labels, scores, and extracted fields may require schema checks or human review.
- Search quality still depends on chunking: poor document splitting or bad metadata can limit results even with a strong model.
When to pick this model
Use Claude for embeddings-adjacent work when you care about semantic quality more than the lowest possible per-item indexing cost. Sonnet 4.6 is usually the best pricing trade-off for production retrieval systems, Haiku 4.5 is the low-cost option for high-volume tagging, and Opus 4.7 is the premium choice when relevance decisions are complex enough to justify $5/M input and $25/M output.
Pick when
- You need semantic classification, extraction, or reranking around a search stack.
- You want one model to handle retrieval logic and answer generation together.
- You are processing long documents where context quality matters more than raw throughput.
- Sonnet 4.6 at $3/M input and $15/M output fits your quality budget.
- You can use prompt caching or Batch API to reduce repeated costs.
Skip when
- You need a clearly defined, dedicated embeddings product rather than a general model.
- Your top priority is the cheapest possible large-scale vector generation.
- You do not need reasoning, only raw nearest-neighbour retrieval.
- Opus-level pricing would make indexing too expensive.
- You want the simplest possible search pipeline with minimal post-processing.
For most teams, the decision rule is simple. Start with Sonnet 4.6 if you are building a RAG or semantic search workflow on the Anthropic API. Move down to Haiku 4.5 if your task is repetitive and cost-sensitive. Move up to Opus 4.7 only when retrieval quality, long-context review, or subtle relevance ranking produces enough business value to offset the higher token cost.
-
Define the actual retrieval job
Separate
vector creation,metadata extraction,query rewriting, andreranking. Claude is usually strongest in the last three. -
Start with Sonnet 4.6
It is the safest default for quality per dollar in production semantic workflows.
-
Benchmark Haiku 4.5 for volume
If labels and extraction quality stay acceptable, the lower token price can materially reduce operating cost.
-
Use Opus 4.7 selectively
Reserve it for difficult ranking or long-document understanding where cheaper models underperform.
| Use case | Best Claude choice | Why |
|---|---|---|
| Bulk topic tagging | Haiku 4.5 | Lowest cost at $1/M input and $5/M output |
| General RAG enrichment | Sonnet 4.6 | Best balance of quality and spend |
| Complex relevance judgments | Opus 4.7 | Highest-end reasoning for difficult ranking |
| Very long document analysis | Opus 4.7 or Sonnet 4.6 | 1,000,000-token context support in the high-end lineup |
Other questions readers ask
Worked example
Choosing a model for document enrichment
That default changes only when your budget is very tight or your relevance task is unusually difficult.
If you are still deciding where this fits, start from the broad Claude AI guide, then compare the current Claude model lineup. Those pages make it easier to separate “general Claude capability” from “specific retrieval architecture choice.”
The honest take
Claude embeddings is a useful search term, but it can be misleading. The current public Claude lineup is centred on general-purpose models — Opus 4.7, Sonnet 4.6, and Haiku 4.5 — not a prominently marketed standalone embeddings family. If your goal is semantic search, RAG, document enrichment, clustering, or reranking, Claude can still be very useful. You just need to treat it as the reasoning and language layer in that system, not assume it replaces every other retrieval component.
For most real workloads, Sonnet 4.6 is the sensible starting point. It gives you strong semantic performance without Opus-level cost. Haiku 4.5 is the budget option for bulk labelling, and Opus 4.7 is worth paying for only when the retrieval judgment is hard enough to matter. If you want the official product experience rather than API architecture details, go straight to Claude itself.
Independent guide. Not affiliated with Anthropic. For the official Claude product, visit claude.ai.
Last updated: 2026-05-12




