
Claude 3.5 Sonnet API pricing is no longer the current Anthropic pricing tier: the closest current replacement is Claude Sonnet 4.6 at $3 per million input tokens and $15 per million output tokens, and this guide explains how that maps to older searches, how billing works, and where costs usually change in practice. For a broader overview, see our Claude pricing guide or the main Claude API hub.

- Free tier · no card
- API priced per million tokens
- The short answer
- How it works
- What it costs
- Limits and gotchas
- Other questions readers ask
- The honest take
The short answer
If you searched for claude 3.5 sonnet api pricing, the practical answer is this: Anthropic’s current general-purpose default is Claude Sonnet 4.6, priced at $3/M input tokens and $15/M output tokens through the API on platform.claude.com. Older searches for Claude 3.5 Sonnet usually mean “what does the mid-tier Claude model cost in the API?”, and today that price point is Sonnet 4.6, not a separate 3.5 listing on the current pricing page.
Anthropic bills API usage by tokens processed, not by request. Input tokens are what you send in the prompt and conversation history. Output tokens are what Claude generates back. If you are comparing model families, the current lineup is simple: Haiku 4.5 is cheapest, Sonnet 4.6 is the balanced default, and Opus 4.7 is the premium option. If you are new to the ecosystem, our independent Claude guide, Claude features overview, and Claude Code guide give the broader context.
| Current model | Position | Input price | Output price |
|---|---|---|---|
| Claude Haiku 4.5 | Fastest and cheapest | $1/M tokens | $5/M tokens |
| Claude Sonnet 4.6 | Recommended default | $3/M tokens | $15/M tokens |
| Claude Opus 4.7 | Flagship | $5/M tokens | $25/M tokens |
Worked example
Simple Sonnet 4.6 API cost
For many app workloads, output tokens drive cost faster than input.
cost = (input_tokens / 1_000_000 * 3) + (output_tokens / 1_000_000 * 15)How it works

Anthropic’s API pricing works on a token-metered model. Each request includes prompt content, system instructions, tool schemas, conversation history, and any other text you send. That becomes input tokens. Claude then returns generated text, structured output, or tool calls, which become output tokens. The API meter tracks both sides separately, so the same request pattern can be cheap or expensive depending on prompt length and answer length.
In practice, developers estimate cost by multiplying total input and output token counts by the model’s listed per-million-token rate from the official pricing documentation, then adjusting for optimisations like prompt caching or the Batch API. Anthropic also documents model capabilities and availability in its models overview. If you need implementation details, the official API docs at docs.claude.com and platform.claude.com are the primary references.
-
Choose the model
Pick
claude-sonnet-4-6for the usual balance of cost and quality,claude-haiku-4-5for low-latency budget work, orclaude-opus-4-7when answer quality matters more than price. -
Count both token directions
Estimate prompt size, conversation history, tool definitions, and expected completion length. A short prompt with a long answer can still cost more on output than input.
-
Apply the model rate
Use the listed per-million-token rates from Anthropic. The basic formula is input spend plus output spend, measured separately.
-
Reduce waste
Use prompt caching when the same long instructions repeat, and use Batch API when your workload is not latency-sensitive.
The key billing mistake is assuming “one API call” has one fixed price. It does not. The token mix matters more than the request count.
What it costs
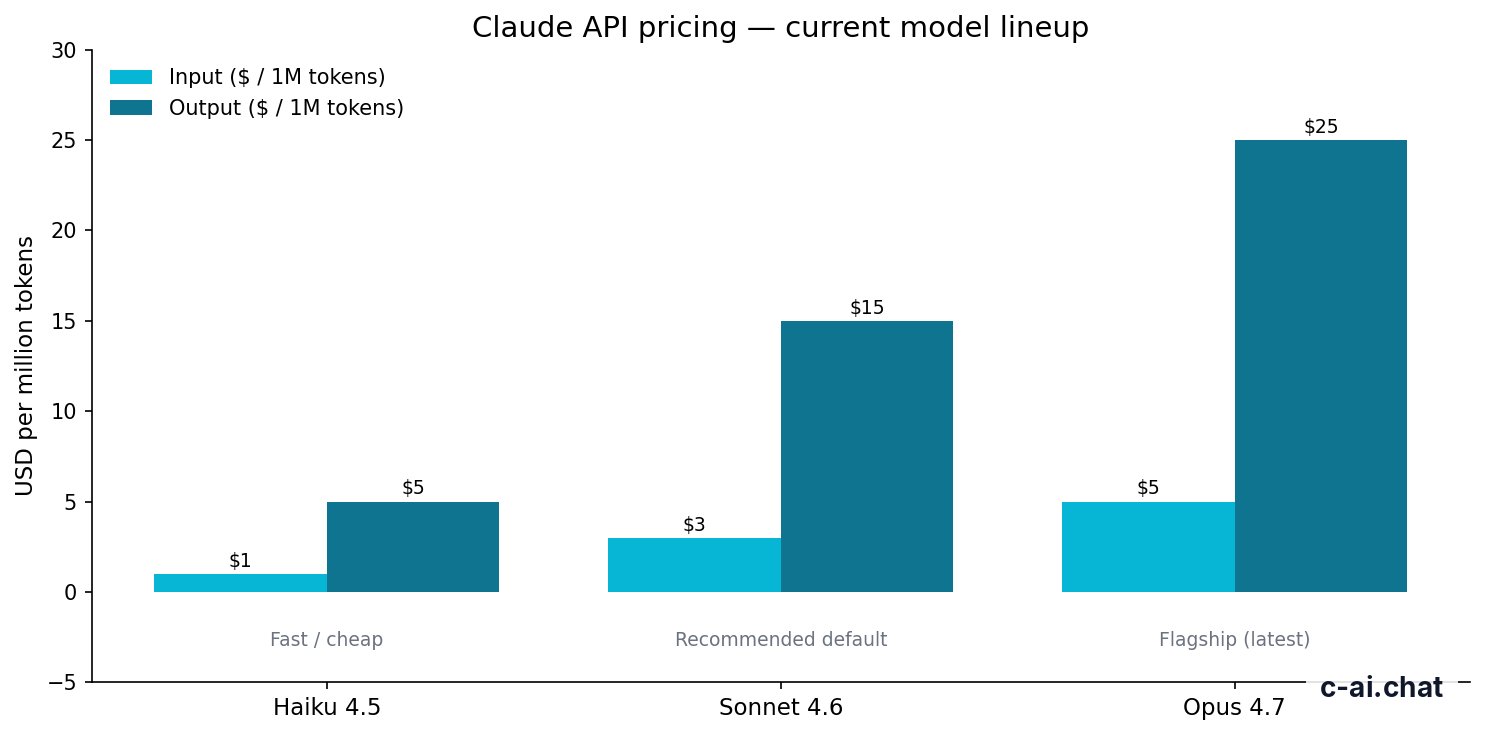
The current Anthropic API pricing relevant to this query is straightforward. Claude Sonnet 4.6 costs $3 per million input tokens and $15 per million output tokens. If you landed here looking for Claude 3.5 Sonnet, treat Sonnet 4.6 as the current equivalent reference point on the active pricing page at claude.com/pricing.
| Model | Input | Output | Best fit |
|---|---|---|---|
| Claude Haiku 4.5 | $1/M tokens | $5/M tokens | High-volume, speed-sensitive tasks |
| Claude Sonnet 4.6 | $3/M tokens | $15/M tokens | General app default |
| Claude Opus 4.7 | $5/M tokens | $25/M tokens | Highest-quality reasoning and output |
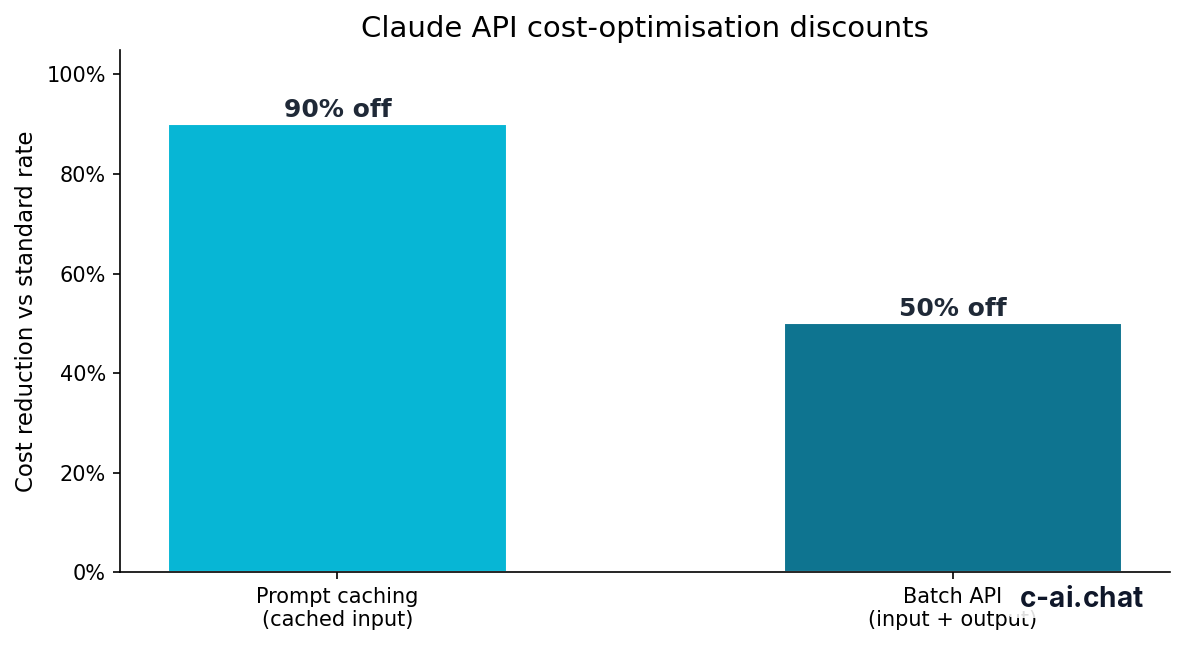
That table covers the base rates. Two official discounts matter a lot in real workloads. Prompt caching gives 90% off cached input tokens. That is useful when you repeatedly send the same large instructions, policy blocks, documents, or tool definitions. Batch API gives 50% off both input and output, which is often the cheapest route for asynchronous jobs such as nightly enrichment, backfills, or content classification.
90% off
cached input tokens with prompt caching
Anthropic also supports long context on the higher-capability models at standard rates. According to the current pricing facts, Opus 4.7, Opus 4.6, and Sonnet 4.6 support up to 1,000,000 tokens of context. Long context is useful, but it can raise cost quickly because every extra token you send is billable input unless it is served from cache.
Pick Sonnet 4.6 when
- You want the default balance of quality, speed, and spend
- You need stronger output than Haiku 4.5 without paying Opus 4.7 rates
- Your app mixes chat, summarisation, extraction, and coding tasks
Skip Sonnet 4.6 when
- Latency and cost matter more than answer quality
- Your workload is simple enough for Haiku 4.5
- You need the highest-end reasoning and can justify Opus 4.7 pricing
For non-API users, Claude also has consumer and team plans on the product side. The current subscription lineup includes Free at $0/month, Pro at $20/month or $17/month annual, Max from $100/month, Team Standard at $25/seat/month or $20/seat/month annual, Team Premium at $125/seat/month or $100/seat/month annual, and Enterprise at $20/seat base plus usage at API rates. Those plans live on the app side, while this page focuses on API billing. If you need the app-plan breakdown, use our pricing guide.
A few budgeting rules help. First, watch output length because it is usually the more expensive side on Sonnet and Opus. Second, avoid resending large static instructions on every turn if prompt caching can cover them. Third, test with real production prompts, not toy examples. Small prompt changes can have a bigger cost effect than switching models.
Limits and gotchas
Developers usually get surprised by limits, availability details, and billing edge cases rather than the list price itself. These are the points to watch before you estimate spend or ship an integration.
- Rate limits are account-specific. Anthropic can apply tiered rate limits by account, model, and usage pattern, so your effective throughput may differ from another developer’s setup.
- Model access can depend on account status. Not every account gets every model immediately. Check your workspace in platform.claude.com before planning around a specific model name.
- Older model names may disappear from current pricing pages. That is why searches for Claude 3.5 Sonnet can be confusing. Current pricing pages list active models, not every historical alias or release.
- Long context is powerful but expensive. A 1,000,000-token window does not mean every request should be huge. Large prompts can dominate cost and latency.
- Prompt history compounds input spend. In chat-style apps, each turn may resend prior context. If you do not trim conversation history, costs rise quietly.
- Tool definitions count as input. Developers often forget that large schemas, instructions, and tool manifests add billable tokens.
- Batch API is cheaper, not faster. The 50% discount is attractive, but it is designed for asynchronous workflows, not user-facing responses.
- Prompt caching helps repeated context only. If each request is mostly new text, the caching discount may not move the total much.
- Regional, compliance, and enterprise controls vary by plan. Features like regional data residency, SCIM, audit logs, role-based access, and spend controls are associated with enterprise offerings, not the default consumer setup.
- Status incidents do happen. If latency or availability matters, monitor status.claude.com instead of assuming a cost issue is always an application bug.
Another common gotcha is mixing up Claude app subscriptions with API usage. Paying for Pro or Max on claude.ai does not mean you get unlimited API tokens included. The API is billed separately through the developer platform. That distinction causes a lot of pricing confusion.
Other questions readers ask
If you are comparing API use with in-product features such as Claude Code or research workflows, the answer changes because those are tied to subscription plans rather than token-metered API usage. For that side of the ecosystem, see our Claude Code guide and feature breakdown.
The honest take
If your search is really “what should I budget for Claude 3.5 Sonnet in the API?”, use Claude Sonnet 4.6 at $3/M input and $15/M output as the current answer. That is the active Sonnet-tier reference on Anthropic’s pricing pages. For most production apps, it is the sensible middle ground between Haiku’s low cost and Opus’s premium pricing.
The bigger pricing issue is rarely the list rate. It is prompt design, repeated context, and output length. Teams that cache repeated prompts, trim conversation history, and reserve Opus for the few tasks that need it usually control spend well. Teams that send huge prompts on every turn usually do not.
Independent guide. Not affiliated with Anthropic. For the official Claude product, visit claude.ai.
Last updated: 2026-05-10
This article is part of the Claude API for developers hub on c-ai.chat.




