
Claude API cost is based on input and output tokens: Opus 4.7 costs $5/M input and $25/M output, Sonnet 4.6 costs $3/M input and $15/M output, and Haiku 4.5 costs $1/M input and $5/M output.

This is an independent c-ai.chat guide, not an Anthropic page. For the broader developer overview, see our Claude API documentation guide. For the official product, use claude.ai. For official API pricing, use Anthropic’s pricing documentation.
- The short answer
- How Claude API pricing works
- Claude API prices by model
- Limits and gotchas
- FAQ
- The practical take
- Sources
- Claude API cost = input token cost + output token cost.
- Prices are listed per million tokens.
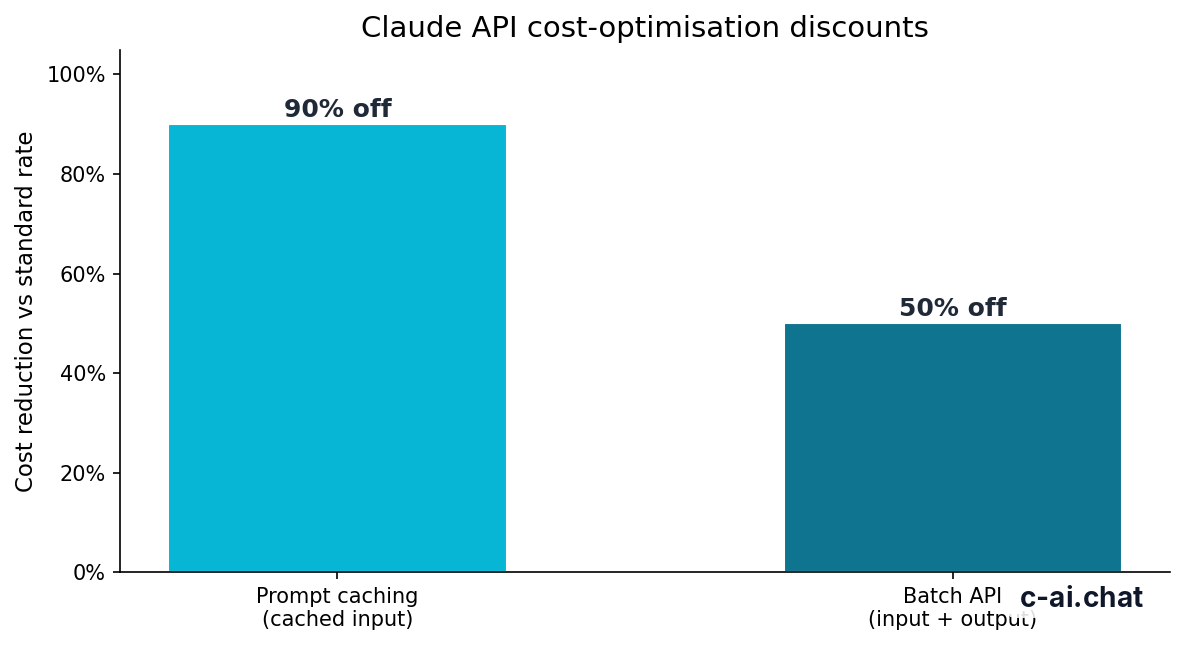
- Prompt caching can reduce cached input cost by 90%.
- Batch API can reduce eligible input and output cost by 50%.
The short answer
To estimate Claude API cost, multiply input tokens by the model’s input rate, multiply output tokens by the model’s output rate, then add the two results.
cost = (input_tokens / 1_000_000 * input_price)
+ (output_tokens / 1_000_000 * output_price)Output tokens often matter more than teams expect. A short prompt that asks for a long answer can cost more than a long prompt that receives a short answer.
Choose the model by task. Use Opus 4.7 for the hardest reasoning work, Sonnet 4.6 as the usual default, and Haiku 4.5 for fast, lower-cost jobs.
Worked example
Sonnet 4.6 request with 20,000 input tokens and 4,000 output tokens
This is the base estimate before prompt caching, Batch API discounts, retries, or app overhead.
If you are comparing API spend with Claude’s web plans, use our Claude pricing guide. Subscription plans and API usage are separate products with different billing models.
How Claude API pricing works

The Claude API counts the tokens you send and the tokens Claude returns. Input tokens include system prompts, user messages, tool definitions, retrieved documents, conversation history, and other content sent to the model. Output tokens are the tokens Claude generates, including text and tool-use instructions.
Your application cost depends on four variables: model, average input size, average output size, and request volume. A support bot with short replies has a different cost profile from a document-analysis workflow that sends large files and asks for structured summaries.
Pick the model
Use Opus 4.7 for demanding reasoning, Sonnet 4.6 for balanced workloads, or Haiku 4.5 for low-latency, lower-cost tasks. Confirm model identifiers in Anthropic’s docs before shipping.
Estimate tokens per request
Measure the average prompt size and expected response size. Include system instructions, conversation history, retrieved context, and tool definitions.
Apply the price formula
Calculate input and output separately. Output tokens cost more, so cap responses when long answers are not needed.
Add volume and failure overhead
Multiply by expected request count. Add margin for retries, invalid responses, tool loops, user re-runs, and test traffic.
Use discounts where they fit
Use prompt caching for repeated context and Batch API for jobs that do not need immediate responses.
A useful calculator should expose separate fields for input tokens, output tokens, model, request count, cacheable input share, and batch share. Hiding those inputs makes estimates look cleaner but less useful.
Real Claude API cost changes when users paste long files, ask for multi-step reasoning, or trigger tool calls that return extra context to the model. If you need help choosing a model, see our Claude models guide.
Claude API prices by model
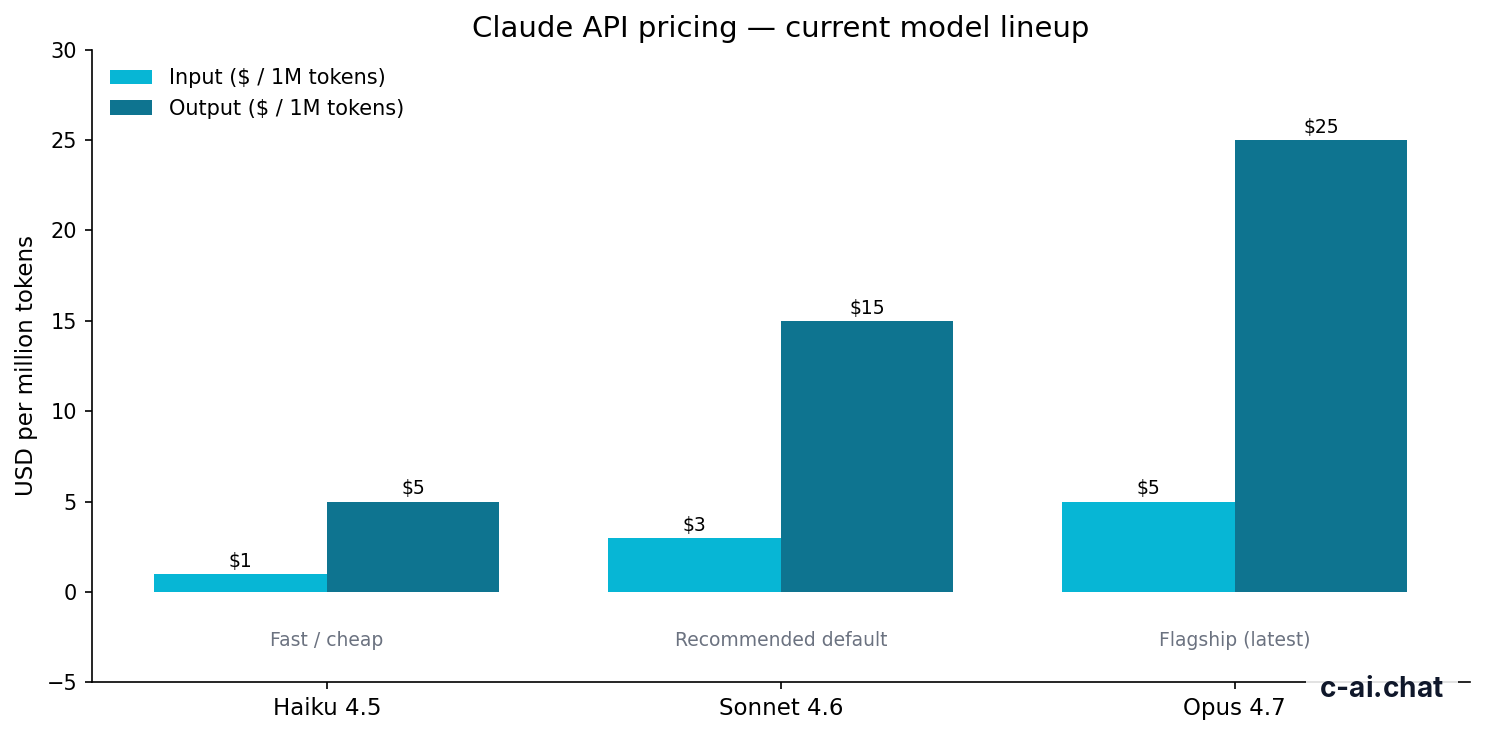
Claude API pricing is per million tokens. Input and output have different prices, and output costs more for each model listed here.
| Model | Best fit | Input price | Output price | Context and output |
|---|---|---|---|---|
| Claude Opus 4.7 | Flagship model for hard reasoning and complex work | $5/M tokens | $25/M tokens | 1M context |
| Claude Sonnet 4.6 | Recommended default for many production apps | $3/M tokens | $15/M tokens | 1M context; 128K max output |
| Claude Haiku 4.5 | Fast, lower-cost classification, extraction, and routing | $1/M tokens | $5/M tokens | Check Anthropic’s docs for current limits |
Model choice
Start with Sonnet 4.6 unless you have a clear reason not to. Move up to Opus 4.7 when quality matters more than token cost. Move down to Haiku 4.5 when the task is narrow, fast, and easy to verify.
Sonnet 4.6 is often the practical middle ground: stronger than a small fast model, but less expensive than Opus for high-volume workloads. Use Opus 4.7 when failure is more expensive than tokens, such as complex code analysis, agent planning, or high-value reasoning tasks.
Use Haiku 4.5 when the task is constrained and measurable. Good examples include intent classification, simple extraction, moderation pre-checks, routing, short rewriting, and metadata generation. For product capabilities, see our guide to Claude features.
90% off
cached input tokens with prompt caching
Prompt caching matters when the same large context appears across many requests. A legal-review app might send the same policy document, schema, and instructions repeatedly while only the user’s question changes. Cached input can reduce the repeated part of the prompt cost.
Batch API matters when latency does not matter. Anthropic’s Batch API offers 50% off both input and output for eligible batch jobs. It fits offline evaluation, bulk summarisation, dataset labelling, and overnight processing. It does not fit chat, interactive copilots, or user-facing flows that need immediate answers.
Use cost optimisations when
- You reuse long instructions or documents across many requests.
- You run large offline jobs that can wait.
- You can cap output length without hurting answer quality.
- You can route easy tasks to Haiku 4.5 and hard tasks to Sonnet 4.6 or Opus 4.7.
Do not rely on them when
- Every prompt is unique and short.
- The user needs a real-time response.
- Your app has unpredictable tool loops.
- You have not measured actual token usage.
One request rarely looks expensive. The cost appears when a product sends many requests, stores long conversation history, retrieves large documents, or asks for verbose answers. Estimate daily and monthly usage, not only a single call.
Worked example
10,000 Sonnet 4.6 requests
If half of the repeated input qualified for cached pricing, the estimate would fall. If users asked for longer responses, it would rise.
Claude web subscriptions are separate from API billing. The web plans have fixed monthly prices and usage limits. API usage is metered by token consumption.
Free
$0
Entry-level Claude web access. API billing is separate.
Pro
$20/mo or $17/mo annual
Individual Claude web subscription. Not the same as API usage.
Max
From $100/mo
Higher-usage Claude web plan. API costs still use token pricing.
Team Standard
$25/seat or $20/seat annual
Team plan for the Claude product experience.
Team Premium
$125/seat or $100/seat annual
Higher-tier team plan for the Claude product experience.
Enterprise
$20/seat base + API rates
Contracted deployment with API usage billed separately.
For official account-level billing, plan availability, and product terms, use Claude’s official pricing page. For system availability, check Claude status.
Limits and gotchas
The math is simple. The surprises usually come from app behavior, limits, and product eligibility.
- Rate limits are not prices. You may be willing to pay for more usage and still hit request-per-minute or token-per-minute limits.
- Output tokens are more expensive than input tokens. Long generated answers can dominate the bill. Set maximum output limits for extraction, classification, and JSON tasks.
- Conversation history grows. Chat apps often resend prior messages. Long threads become expensive unless you summarise, truncate, or retrieve only relevant context.
- Tool use can add token volume. Tool definitions, tool results, and follow-up calls can increase both input and output. Agent loops need strict stopping rules.
- Model availability can differ. Availability can vary by account, region, or product surface. Confirm current availability in Anthropic’s model docs and your API account.
- Compliance requirements can affect deployment. Enterprise controls, regional data residency, and regulated workflows may require a specific plan or contract.
- Prompt caching is not automatic savings on every token. It helps most when repeated context is stable and cacheable. It helps less when prompts are short or unique.
- Batch API trades latency for price. The discount is useful for offline work, but it is not a replacement for real-time API calls.
- Retries can inflate cost. Network failures, validation failures, overloaded tools, or JSON parsing issues can cause duplicate calls.
- Errors can hide cost problems. Rate-limit errors, context-length errors, invalid model names, authentication failures, and malformed tool schemas can all create wasted test cycles.
A strong cost-control setup logs model name, input tokens, output tokens, cache usage, latency, status code, retry count, and feature name for every request. That lets you find expensive product flows instead of guessing from the total bill.
For operational planning, pair cost logs with rate-limit handling, status monitoring, and a clear fallback strategy. Our Claude resources page collects related guides for implementation planning.
FAQ
If your question is about the Claude app rather than the API, start with our independent Claude guide or our Claude FAQ. The API and Claude web app share model families, but they are different ways to use Claude.
The practical take
Claude API cost is predictable once you measure tokens. The main mistake is treating a single request estimate as the whole budget. Real spend comes from output length, repeated context, conversation history, retries, and product flows that call the model more often than expected.
Start with Sonnet 4.6, log token usage by feature, and move tasks up or down the model lineup after testing. Use Opus 4.7 where quality justifies the higher output price. Use Haiku 4.5 where the task is narrow and easy to evaluate. Use prompt caching and Batch API when their trade-offs match your workload.
Independent guide. Not affiliated with Anthropic. For the official Claude product, visit claude.ai.
Last updated: 2026-05-12
This article is part of the Claude API for developers hub on c-ai.chat.




