Claude generations usually means the progression from Claude 2 to Claude 3 and now Claude 4, and the current lineup is best understood by family first: Opus, Sonnet, and Haiku, then by version number such as Opus 4.7, Sonnet 4.6, or Haiku 4.5. c-ai.chat is an independent guide, not Anthropic, and this page explains what changed across generations, which model sits where, and how to choose the right one.

If you came here looking for pricing rather than capabilities, start with our Claude pricing guide. If you want the broader product overview first, see the c-ai.chat homepage or our overview of Claude features.
- Which model is this?
- What it’s best at
- Where it falls short
- When to pick this model
- Other questions readers ask
- The honest take
Which model is this?

Today, “Claude generations” maps to three practical eras: Claude 2, Claude 3, and Claude 4. For most people, the important point is this: the current generation is Claude 4, and within it you choose a family and version — Opus 4.7 as the flagship, Sonnet 4.6 as the default recommendation, and Haiku 4.5 as the fast, low-cost option.
That means a model should be identified precisely by family + version. “Claude 4” on its own is too vague if you are comparing quality, speed, or API cost. In Anthropic’s current lineup, Opus 4.7 is the latest top-tier model, Sonnet 4.6 is the balance pick, and Haiku 4.5 is the lightweight option for cheaper, faster work. Developers can compare the current API lineup in our Claude API guide and the model directory on platform.claude.com.
- Opus 4.7 · flagship family, latest version in the Opus line
- Input $5 per million tokens
- Output $25 per million tokens
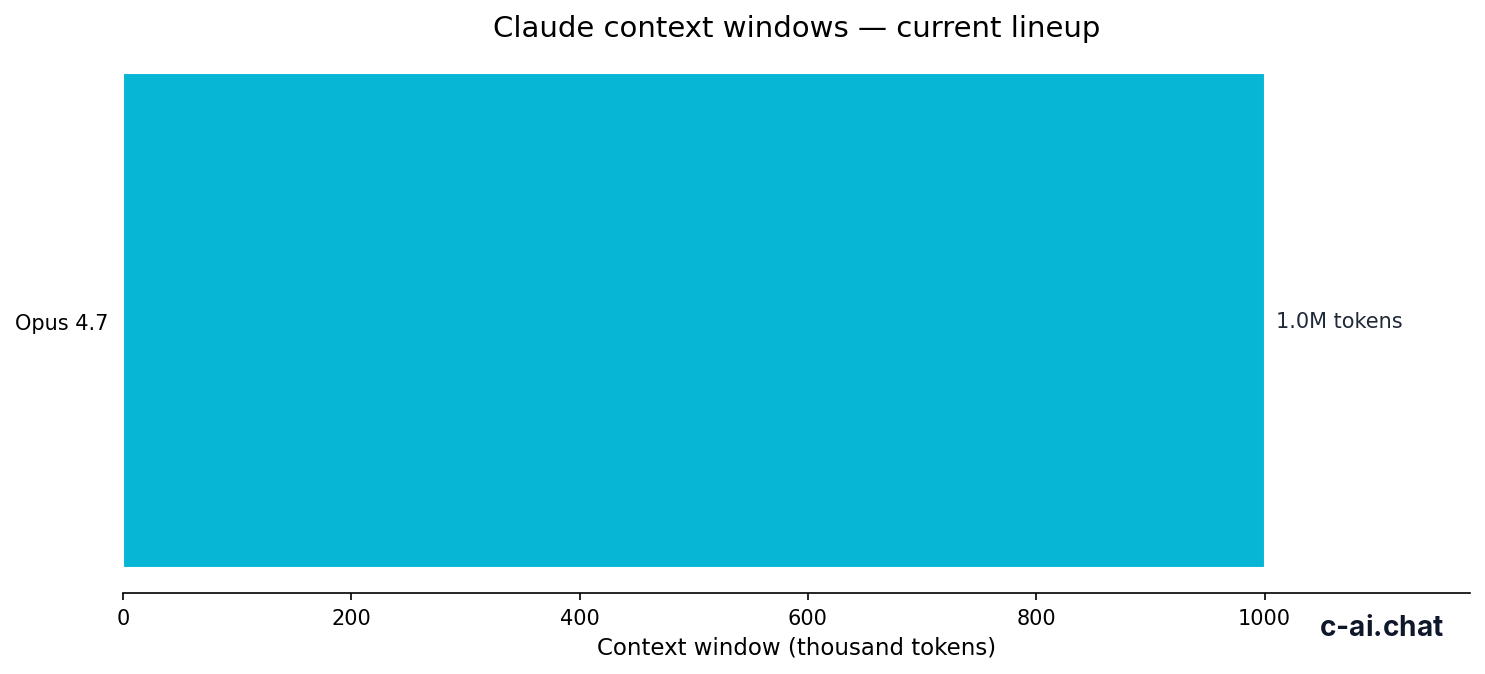
- Context window 1,000,000 tokens
- Max output model-dependent limits apply; Sonnet 4.6 is documented at 128K max output
| Generation | What changed | How to think about it now |
|---|---|---|
| Claude 2 | Older generation with weaker reasoning and coding than current models | Mainly historical context |
| Claude 3 | Introduced clearer model tiering across Opus, Sonnet, and Haiku | Important stepping stone, but not the current peak |
| Claude 4 | Current generation with stronger reasoning, coding, and long-context performance | The lineup most users should choose from today |
| Opus 4.7 | Highest quality in the current stack | Pick for hard reasoning and demanding code work |
| Sonnet 4.6 | Best balance of cost and capability | Default choice for most users |
| Haiku 4.5 | Lowest-cost, fastest tier | Pick for scale, speed, and lighter tasks |
What it’s best at
Across Claude generations, the biggest practical jump is not just “newer is better.” It is that the lineup has become easier to segment by job type. Claude 4 gives you a clearer split between premium reasoning and coding work on Opus, general-purpose professional work on Sonnet, and high-volume low-cost tasks on Haiku. If you are choosing from the current generation, Sonnet 4.6 is the safest starting point for most people, while Opus 4.7 is the model you move to when quality matters more than price.
Compared with older Claude generations, the current models are stronger on sustained reasoning, code generation, long-context document handling, and enterprise workflows. Compared with its sibling models, Opus 4.7 is better than Sonnet 4.6 at difficult multi-step reasoning and harder coding tasks, while Sonnet 4.6 is usually the better value. Haiku 4.5 gives up some depth but wins on speed and cost for simpler workloads. You can see the broader family breakdown in our Claude models guide.
- Hard reasoning tasks: Opus 4.7 is the strongest pick for nuanced analysis, complex planning, and long chains of thought that need fewer compromises.
- Everyday professional work: Sonnet 4.6 is usually the best fit for writing, coding, analysis, and document work at a lower price than Opus.
- Large-document handling: current top models support a 1,000,000-token context window, which materially changes how much source material you can keep in one session.
- High-volume automation: Haiku 4.5 is well suited to classification, extraction, templated outputs, and lightweight support tasks.
- API production workloads: the current generation is easier to optimize thanks to prompt caching and Batch API discounts documented on platform.claude.com.
90% off
cached input tokens with prompt caching
| Current model | Best for | Input price | Output price | Relative position |
|---|---|---|---|---|
| Opus 4.7 | Top-end reasoning, advanced coding, highest-stakes outputs | $5/M | $25/M | Highest quality, highest cost |
| Sonnet 4.6 | General-purpose work, strong coding, balanced production use | $3/M | $15/M | Best balance |
| Haiku 4.5 | Fast, cheaper inference, high-volume lighter tasks | $1/M | $5/M | Lowest cost, lightest tier |
One useful way to read “Claude generations” is that Claude 3 established the family structure, while Claude 4 made the current lineup the one that matters in day-to-day buying decisions. If you are not sure where to start, Sonnet 4.6 is usually the right answer until your workload proves you need Opus quality or Haiku economics.
Where it falls short

The weak spot in any “Claude generations” discussion is assuming the newest flagship is always the best practical choice. Opus 4.7 is the strongest model, but it also has the highest output cost at $25 per million tokens, so it is easy to overspend if your workload does not need that level of reasoning. Sonnet 4.6 is cheaper but still not the lowest-cost option, and Haiku 4.5 can be the wrong pick if you need depth, subtle judgment, or stronger code performance.
- Opus 4.7 can be expensive at scale: if your app generates lots of output, output-token cost matters more than many teams expect.
- Sonnet 4.6 is not the absolute cheapest: it is a value pick, not the budget pick. Haiku 4.5 is better when cost and latency dominate.
- Haiku 4.5 is not ideal for the hardest reasoning: use it for lighter workloads, not your most nuanced tasks.
- Older generation names are still common in search results: that can confuse buyers who are actually comparing obsolete models against the live lineup.
- Long context does not erase prompt quality problems: a 1,000,000-token window is powerful, but messy prompts and weak retrieval logic still produce weak outputs.
-
Check the task before you check the generation
If the task is simple extraction or routing,
Haiku 4.5may beat a newer flagship on cost efficiency. -
Estimate output volume
For verbose assistants or report generation, output pricing often drives the real bill more than input pricing.
-
Benchmark against Sonnet first
Sonnet 4.6is the baseline many teams should test before paying more for Opus.
When to pick this model
The decision rule is simple: pick the model tier that matches the job, then only pay more when the quality gain is real. Across Claude generations, the current lineup is mature enough that you can usually map one model to one workload pattern without much guesswork.
Pick when
- You want the current default for most work: Sonnet 4.6 at $3/M input and $15/M output.
- You need top-end reasoning or coding and can justify Opus 4.7 at $5/M input and $25/M output.
- You need cheaper, faster throughput and can accept lighter capabilities with Haiku 4.5 at $1/M input and $5/M output.
- You want the latest Claude generation rather than comparing against retired or older naming.
Skip when
- You are choosing purely by generation number instead of testing the actual task.
- You assume the flagship is automatically the best value for production workloads.
- Your workload is cost-sensitive and you have not modeled token output volume.
- You need a simple answer to plan pricing rather than model pricing; see Claude plans and pricing instead.
Worked example
Why generation alone is not enough for API buying
The newer generation gives you better options, but the right option still depends on the task and budget.
Other questions readers ask
| Plan | Price | Who it is for | What matters here |
|---|---|---|---|
| Free | $0/month | Casual users | Daily usage limits |
| Pro | $20/month or $17/month annual | Individuals | More usage, Claude Code, Claude Cowork, unlimited Projects, Research access, additional models, Office integrations |
| Max | From $100/month | Power users | 5x or 20x Pro usage, higher output limits, early features, priority traffic |
| Team Standard | $25/seat/month or $20/seat/month annual | Small teams | Shared workspace, SSO, admin controls |
| Team Premium | $125/seat/month or $100/seat/month annual | Higher-capacity teams | Priority traffic, expanded admin controls |
| Enterprise | $20/seat base + usage at API rates | Larger organisations | SCIM, audit logs, HIPAA-ready options, regional data residency, spend controls |
- Free tier · no card
- API priced per million tokens
The honest take
If you search for claude generations, the clean answer is that the current generation is Claude 4, and the buying decision now happens mostly inside that generation. Opus 4.7 is the flagship, Sonnet 4.6 is the best general-purpose choice, and Haiku 4.5 is the cost-and-speed option. Older generation names still matter for comparison, but they are not the center of the practical decision anymore.
For most readers, the right move is to stop asking “Which generation is best?” and ask “Which current model fits my workload?” Start with Sonnet 4.6, move to Opus 4.7 when quality is worth the extra output cost, and use Haiku 4.5 when scale and budget matter more than depth. For the official product, use claude.ai; for independent reference material, keep browsing c-ai.chat.
Independent guide. Not affiliated with Anthropic. For the official Claude product, visit claude.ai.
Last updated: 2026-05-15