Claude context comparison is mostly a question of model family and output limits: Claude Opus 4.7 offers a 1,000,000-token context window at flagship quality, Claude Sonnet 4.6 balances cost and capability, and Claude Haiku 4.5 is the faster, cheaper option for lighter work. This is c-ai.chat, an independent guide to Claude by Anthropic, and if you want the broader model lineup first, see our Claude models guide.

- Which model is this?
- What it’s best at
- Where it falls short
- When to pick this model
- Other questions readers ask
- The honest take
Which model is this?

For a claude context comparison, the key split is simple: Opus is the flagship family, Sonnet is the default recommendation for most people, and Haiku is the low-cost speed option. In the current lineup, Claude Opus 4.7 is the latest Opus version, Claude Sonnet 4.6 is the main mid-tier choice, and Claude Haiku 4.5 is the lightweight model; Anthropic lists Opus 4.7 as released on 2026-04-16.
- Opus 4.7 · $5/M input · $25/M output
- Sonnet 4.6 · $3/M input · $15/M output
- Haiku 4.5 · $1/M input · $5/M output
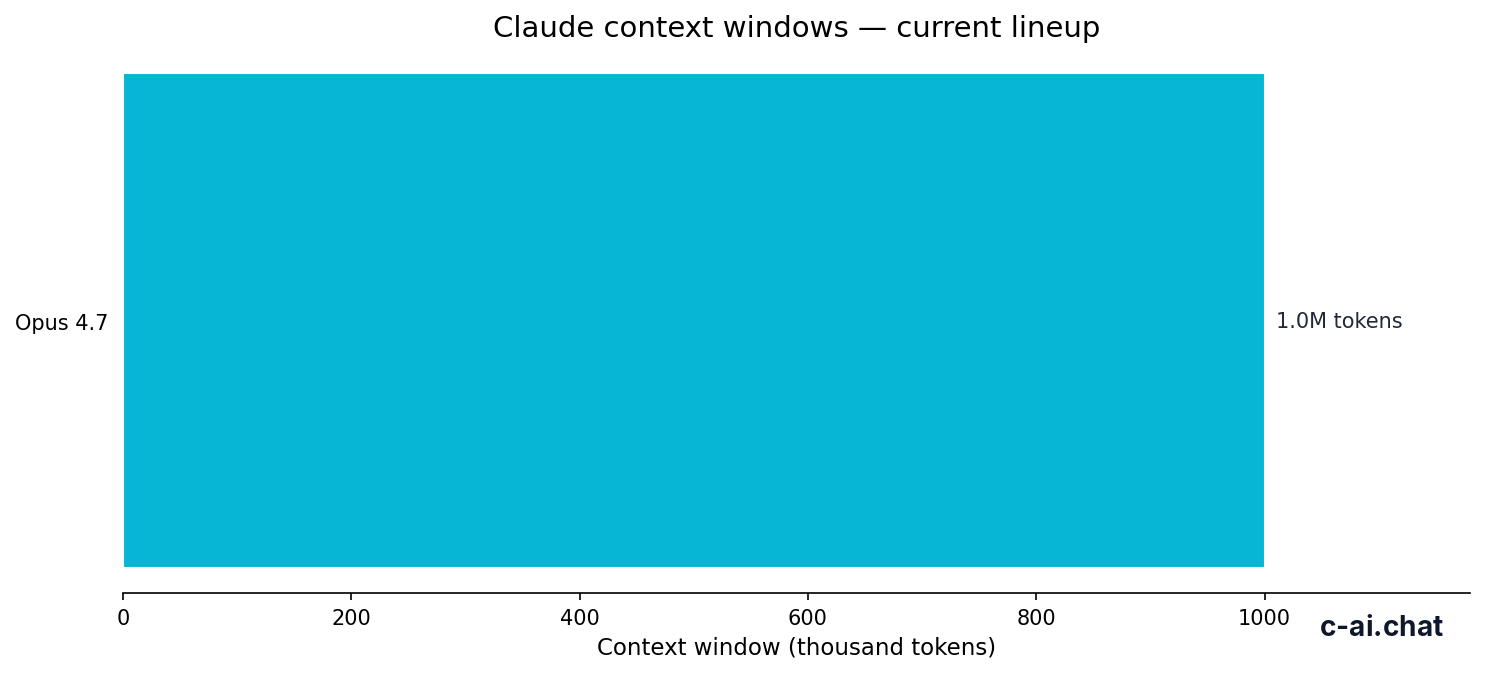
- Context window · up to 1,000,000 tokens on Opus 4.7 and Sonnet 4.6
- Max output · Sonnet 4.6 supports up to 128K output
If you are comparing Claude models by context window alone, the headline is that long context is not the main separator between the top two choices. Opus 4.7 and Sonnet 4.6 both support very large context, so your real decision is usually quality versus price. Haiku 4.5 matters when speed and lower cost matter more than deep reasoning. You can cross-check current rates in our Claude pricing guide and API-specific details in our Claude API overview.
| Model | Family | Input price | Output price | Context window | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.7 | Opus | $5/M tokens | $25/M tokens | 1,000,000 tokens | Highest-stakes reasoning, long complex work |
| Claude Sonnet 4.6 | Sonnet | $3/M tokens | $15/M tokens | 1,000,000 tokens | Default choice for most users and teams |
| Claude Haiku 4.5 | Haiku | $1/M tokens | $5/M tokens | Smaller context than the long-context top tiers | Fast, cheap classification and lightweight generation |
1M tokens
context window on Claude Opus 4.7 and Claude Sonnet 4.6
What it’s best at
In practical terms, Claude context comparison is less about “which model can read the most” and more about “which model makes the best use of a large prompt.” Opus 4.7 is the strongest pick when you need the model to track many moving parts across a long document set, reason through edge cases, and produce careful output that holds together over extended conversations. If you are working with legal-style documents, large codebases, multi-step research notes, or long project memory, Opus 4.7 is the model that gives you the most headroom.
Sonnet 4.6 is usually the better default because it keeps the large-context benefit while costing less: $3/M input and $15/M output instead of Opus 4.7’s $5/M and $25/M. For many business and developer tasks, that trade-off is the sweet spot. Haiku 4.5 still has a role, but it is the sibling you pick when low latency and low cost matter more than squeezing the best reasoning out of a large context window. If you want a broader feature view beyond context size, our Claude features guide covers the workflow side.
- Long-document analysis: comparing contracts, policies, research notes, or transcripts without aggressively chopping them into smaller pieces.
- Large code context: reviewing multiple files, tracing dependencies, and answering questions about architecture across a bigger code sample.
- Project memory: keeping prior instructions, style rules, references, and examples in context for more consistent outputs.
- Multi-source synthesis: combining notes, internal docs, and user prompts into one answer with fewer handoffs.
- High-stakes drafting: tasks where Opus 4.7’s stronger reasoning may justify its higher price over Sonnet 4.6.
Where it falls short

The weak point in most Claude context comparisons is assuming the largest context always wins. It does not. Large context can raise cost, increase latency, and encourage messy prompting if you keep dumping everything into the model. In many everyday tasks, Sonnet 4.6 is the better choice because it gives you much of the same long-context flexibility at a lower price, and Haiku 4.5 is better when the task is simple enough that premium reasoning is wasted.
- Cost-sensitive workloads: Opus 4.7 is harder to justify if you are processing high volume and the answers do not need flagship reasoning.
- Simple classification or extraction: Haiku 4.5 is often the smarter pick for routine pipelines.
- Short prompts and quick replies: Sonnet 4.6 usually offers a better price-performance balance.
- Overstuffed prompts: more context can bury the important signal unless you structure the input well.
- Output-heavy jobs: output tokens are expensive, especially on Opus 4.7, so long responses can move total cost faster than expected.
Worked example
Why context size is not the whole pricing story
When usage scales up, the model choice matters more than the headline context window.
When to pick this model
The decision rule is straightforward: pick Opus 4.7 when answer quality on long, difficult inputs matters more than price; pick Sonnet 4.6 when you want long context with better economics; pick Haiku 4.5 when the task is routine and throughput matters most. The pricing trade-off is explicit: Opus 4.7 costs $5/M input and $25/M output, Sonnet 4.6 costs $3/M and $15/M, and Haiku 4.5 costs $1/M and $5/M.
Pick when
- You need long-context reasoning across many documents or files.
- You care about answer quality more than minimum cost.
- You want a default model for serious work and can pay for better output.
- You are choosing Sonnet 4.6 as the balanced option or Opus 4.7 for the hardest tasks.
Skip when
- Your prompts are short and your workflow is mostly simple Q&A.
- You are processing large volumes where token cost dominates.
- You mainly need speed, tagging, extraction, or lightweight generation.
- Haiku 4.5 gives acceptable quality at a much lower price.
For API users, cost controls matter as much as the model. Anthropic also offers prompt caching with 90% off cached input tokens and Batch API pricing with 50% off both input and output, which can change the economics of large-context workflows. If your use case is operational rather than conversational, start with the API guide and then compare model costs in our pricing breakdown.
90% off
cached input tokens with prompt caching
Other questions readers ask
The honest take
The honest answer on claude context comparison is that context size is now less of a differentiator at the top of the lineup than many search results suggest. If you want the strongest long-context model, Opus 4.7 is the premium choice. If you want the best default, Sonnet 4.6 is the one most people should start with because it still offers 1,000,000-token context at lower cost. If you mostly care about speed and spend, Haiku 4.5 is the practical choice.
So the right question is not just “which Claude model has the biggest context window?” It is “which Claude model gives me enough context at the right price for my workload?” For most users, that answer is Sonnet 4.6. For demanding reasoning, it is Opus 4.7. For lean pipelines, it is Haiku 4.5.
Independent guide. Not affiliated with Anthropic. For the official Claude product, visit claude.ai.
Last updated: 2026-05-12