
Claude prompt caching lets API developers reuse large, repeated prompt prefixes so cached input tokens cost 90% less on later requests. c-ai.chat is an independent guide, not Anthropic; for broader developer context, see our Claude API guide.

- The short answer
- How prompt caching works
- Claude prompt caching pricing
- Limits and gotchas
- FAQ
- The practical verdict
- Sources
The short answer
Prompt caching is a Claude API feature for prompts that reuse the same large context across many calls. Good examples include system instructions, product documentation, codebase files, policy manuals, tool schemas, and stable retrieval results.
You mark the reusable part of the request with cache control. The first matching request creates or refreshes the cache. Later requests that reuse the same eligible prefix can receive the cached-input discount. Put the user-specific part after the cached block so it does not change the reusable prefix.
90% off
cached input tokens with Claude prompt caching
- Prompt caching helps with large repeated prefixes, not one-off prompts.
- It works through the Claude API, not as a manual toggle in claude.ai.
- It discounts cached input tokens. It does not discount output tokens.
- It works best with stable instructions, docs, examples, tool schemas, and code context.
Minimal API pattern
Put reusable context before the changing request
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY
});
const message = await client.messages.create({
model: "MODEL_NAME_FROM_ANTHROPIC_DOCS",
max_tokens: 800,
system: [
{
type: "text",
text: "You are the support assistant for Acme. Follow the policy manual below."
},
{
type: "text",
text: "LONG_REUSABLE_POLICY_MANUAL_OR_DOCS_GO_HERE",
cache_control: { type: "ephemeral" }
}
],
messages: [
{
role: "user",
content: "Customer asks: Can I get a refund after 45 days?"
}
]
});
console.log(message.content);Use the model identifier and request format from Anthropic’s current documentation. Keep the cached material stable. Move the changing user question after it.
Anthropic documents prompt caching in its developer docs. Check the official prompt caching documentation, API pricing docs, and model overview before building cost assumptions into production software.
How prompt caching works
Claude prompt caching identifies a stable prefix in your request. That prefix is the part you would otherwise send again and again: a long system prompt, style guide, source files, contracts, product catalogue, examples, or reference documents.
You attach cache control metadata to the reusable content block. When a later request sends the same eligible prefix, Anthropic can read from the cache instead of processing all of those input tokens at the normal uncached input rate.
Order matters. Cached content should appear before variable content. If the user’s changing question comes before the large document, the prefix changes on every request and the cache is less likely to help. If the large document comes first and each new question follows it, repeated calls are more likely to register cache hits.
Identify the repeated prefix
Find the content that appears unchanged across many requests: policy text, a code bundle, a product catalogue, examples, or fixed instructions.
Move variable text after it
Put the user’s question, ticket, file diff, or task after the reusable context.
Add cache control
Mark the reusable content with
cache_controlusing the format supported by Anthropic’s Messages API.Measure cache reads and misses
Log usage fields from API responses. Treat cache misses as normal during warm-up, prompt changes, and low-volume traffic.
Refactor prompts when needed
If cache hits stay low, split static and dynamic content more cleanly.
Prompt caching is not semantic memory. Claude does not remember the meaning of a document and apply it to unrelated prompts. The cache is tied to the reusable input structure you send through the API. For the official Claude app, visit claude.ai. For a broader product overview, see Claude features explained.
Claude prompt caching pricing

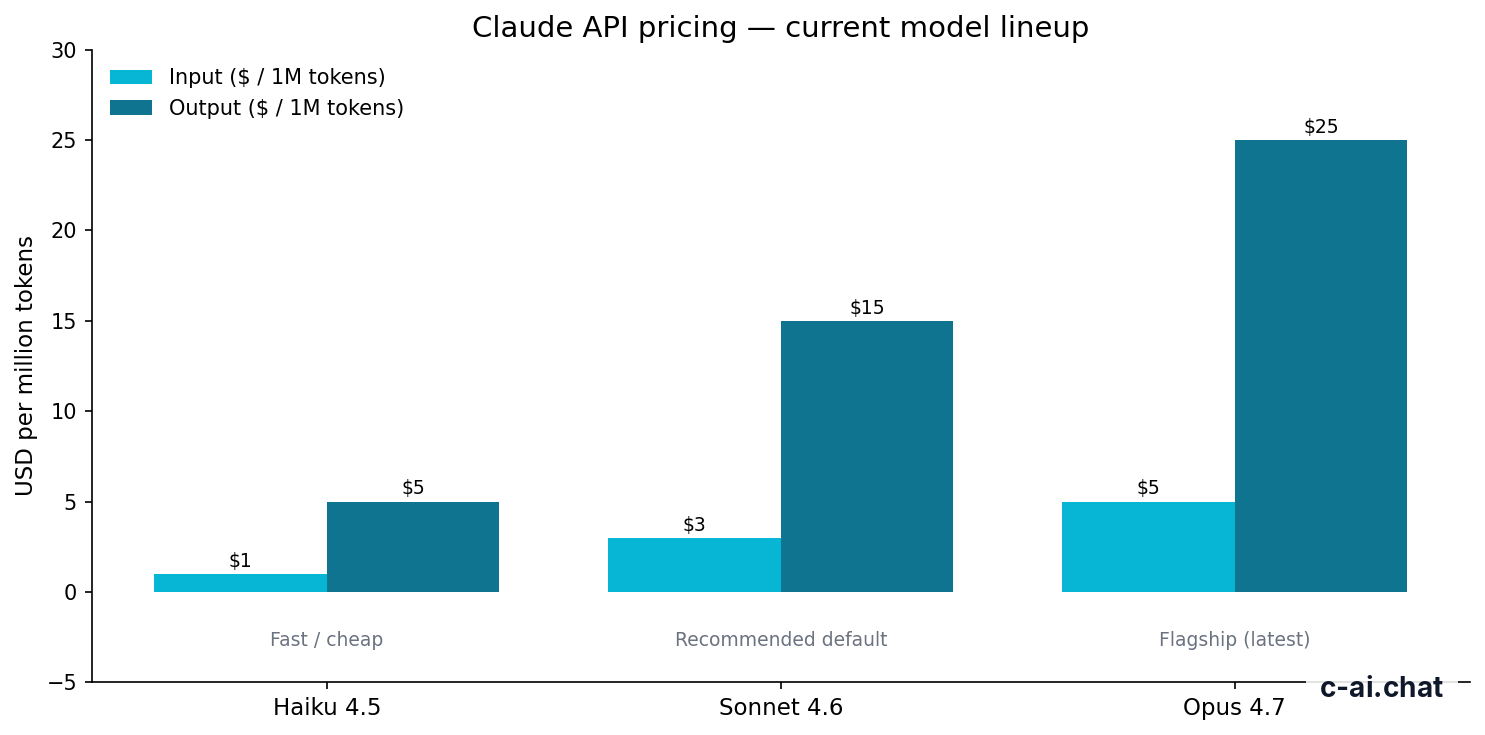
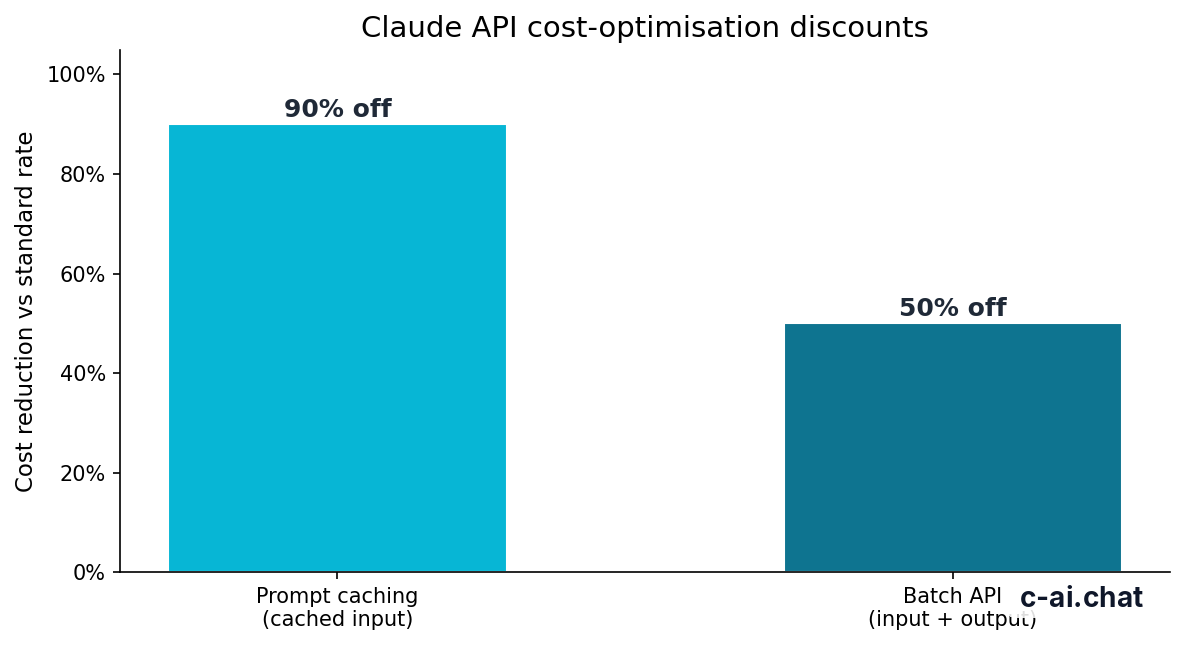
Claude API pricing is token-based. Input tokens are text you send to the model. Output tokens are text the model generates. Prompt caching affects repeated input tokens, not generated output. Cached input tokens are 90% off.
The base model prices below are standard per-million-token API rates for the active Claude model lineup. Check Anthropic’s official Claude pricing page and API pricing docs before shipping billing logic.
Claude Opus 4.7
$5/M input tokens
$25/M output tokens
Flagship model. 1M context.
Claude Sonnet 4.6
$3/M input tokens
$15/M output tokens
Best balance. 1M context and 128K max output.
Claude Haiku 4.5
$1/M input tokens
$5/M output tokens
Fastest and cheapest active Claude model.
| Model | Best fit | Input price | Output price | Cached input effect |
|---|---|---|---|---|
| Claude Opus 4.7 | Demanding reasoning and long-context work | $5/M tokens | $25/M tokens | 90% off cached input tokens |
| Claude Sonnet 4.6 | Quality, latency, and cost balance | $3/M tokens | $15/M tokens | 90% off cached input tokens |
| Claude Haiku 4.5 | Fast, lower-cost tasks at scale | $1/M tokens | $5/M tokens | 90% off cached input tokens |
A simple rule: if you send the same long reference document to Claude many times, prompt caching reduces the cost of rereading that document after it is cached. It does not reduce the cost of a brand-new prompt prefix. It does not reduce output token costs.
Worked example
Repeated policy manual with Sonnet 4.6
The largest savings appear when the cached prefix is large and reused across many requests.
Prompt caching also interacts with other cost controls. Anthropic’s Batch API can reduce costs by 50% in both directions for eligible batch workloads. Batch processing helps when latency is flexible. Prompt caching helps when repeated context would otherwise be resent at normal input rates. For a broader billing comparison, see our Claude pricing guide.
For model selection and context-window tradeoffs, see our Claude models guide.
Limits and gotchas
The most common mistake is assuming prompt caching makes every Claude request cheaper. It does not. It helps only when you send an eligible repeated prefix in a form the API can reuse.
- Cache misses during warm-up: the first request with a new reusable prefix may not receive the cached-read discount because the cache has to be created or refreshed.
- Small prompt changes can matter: editing the cached block, changing content order, or adding variable text before the cached section can reduce cache hits.
- Minimum prompt sizes may apply: very small prompts are poor candidates. Check Anthropic’s docs for supported lengths and content types.
- Rate limits still apply: prompt caching reduces token-processing cost for repeated input. It does not remove API rate limits, account limits, or usage ceilings.
- Model support can differ: do not assume every Claude model, endpoint, or request format supports the same caching behavior.
- Enterprise controls can affect deployment: security, compliance, and data-handling requirements may change the right setup for your organisation. Use Anthropic’s Trust Center for official security and compliance information.
- Output is not discounted by caching: generated tokens still use the model’s output price.
- Cache lifetime is not permanent memory: prompt caching is a request optimisation, not a user profile, vector database, or application memory layer.
- Common API errors are usually structural: invalid cache control placement, unsupported block shapes, outdated SDK versions, or old model names can cause failures.
- Status incidents can change behavior: if a working integration suddenly fails, check the official Claude status page before rewriting your code.
Use prompt caching when
- You reuse the same long context many times.
- The variable user request can come after the static context.
- You can track usage fields and cache hit rates.
- Your latency needs fit Anthropic’s supported API flow.
Skip prompt caching when
- Every request has unique context.
- Your prompt is short and savings are negligible.
- You cannot keep the prefix stable.
- You need persistent memory rather than repeated-prefix reuse.
For production use, track cached tokens, uncached tokens, output tokens, latency, and errors. A prompt that looks cache-friendly in a notebook may behave differently after retrieval, templating, tool schemas, or user-specific metadata are added.
FAQ
The practical verdict
Claude prompt caching is useful when repeated context is a real part of your workload. Support bots with a fixed policy manual, coding assistants with stable repository context, contract-review tools with standard playbooks, and internal copilots with repeated documentation are good candidates.
Short prompts, one-off tasks, and constantly changing retrieval results are weaker fits. Measure how many input tokens repeat across calls. If that number is large, prompt caching can cut a meaningful part of your Claude API bill. If output tokens dominate or every prompt prefix changes, choose a cheaper model, reduce response length, use batching where latency allows, or redesign the prompt.
Last updated: 2026-05-12
This article is part of the Claude API for developers hub on c-ai.chat.




